背景
YOLOv7 在 5 FPS 到 160 FPS 范围内,速度和精度都超过了所有已知的目标检测器,并在 GPU V100 上,30 FPS 的情况下达到实时目标检测器的最高精度 56.8% AP。YOLOv7 是在 MS COCO 数据集上从头开始训练的,不使用任何其他数据集或预训练权重。

YOLOv7 在 5 FPS 到 160 FPS 范围内,速度和精度都超过了所有已知的目标检测器,并在 GPU V100 上,30 FPS 的情况下达到实时目标检测器的最高精度 56.8% AP。YOLOv7 是在 MS COCO 数据集上从头开始训练的,不使用任何其他数据集或预训练权重。
通过编写 Python 代码来负责 Docker 和开发环境的设置,因为开发环境充满了 Dockerfile、bash 脚本、Kubernetes YAML 清单以及许多其他总是会中断的笨重文件。envd构建是隔离和干净的。你可以用 Python 编写简单的指令,而不是 Bash / Makefile / Dockerfile / ...,并且envd提供可重复的构建和可重现的结果。
- conda yaml环境配置文件
- 编写的wrapper.py文件
- 模型的代码文件
- 业务的base镜像
- 通过配置文件编写的build.envd文件
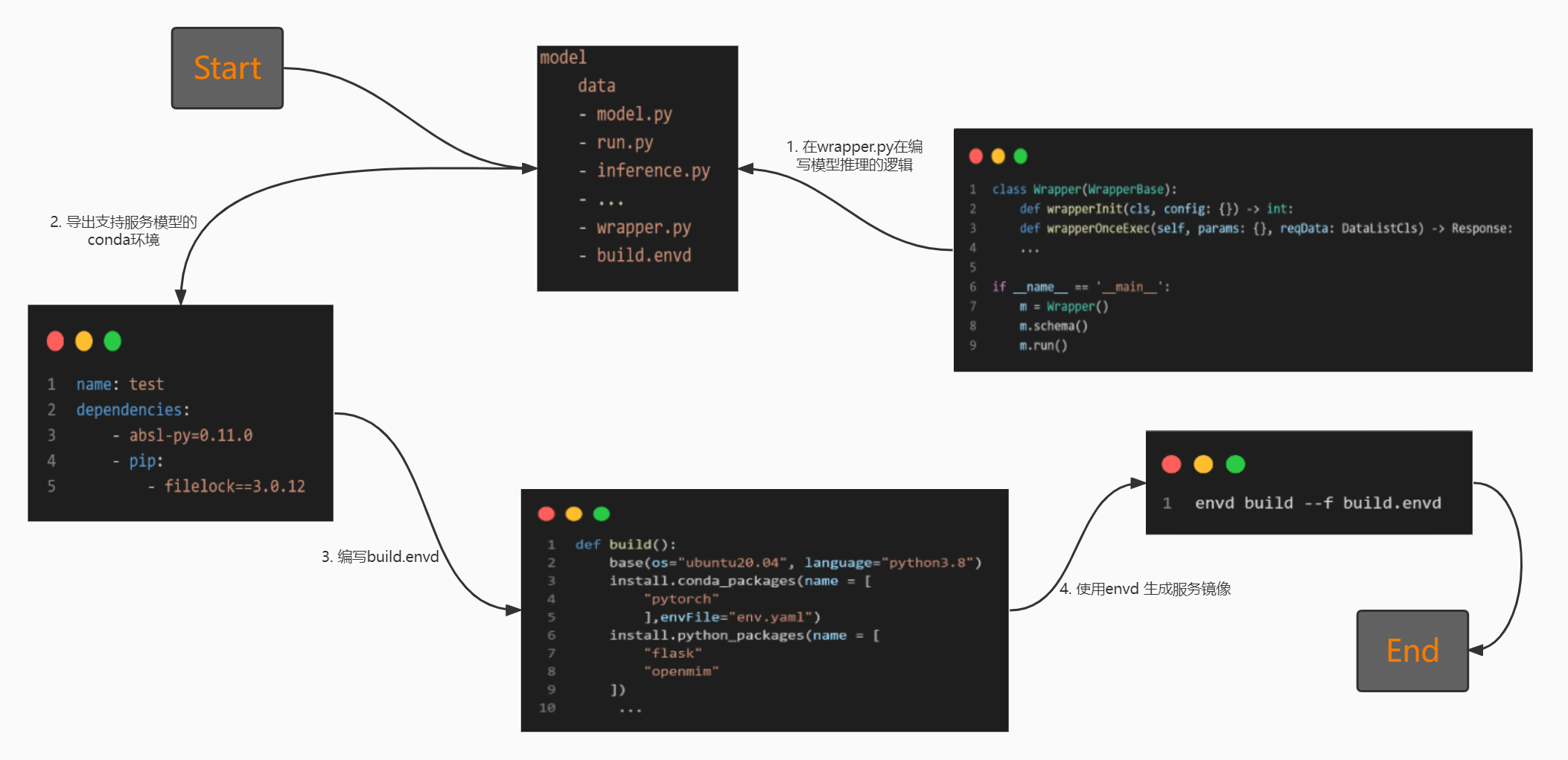
pip install --pre --upgrade envd
envd bootstrap
name: kyle
channels:
- https://repo.anaconda.com/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- defaults
dependencies:
- requests
- pip:
- opencv-python==4.1.2.30
prefix: C:\ProgramData\Anaconda3\envs\kyle
def build():
mirror_config()
base(language="python3.8", os="ubuntu20.4") # 加载基础镜像并设置conda内置的python版本
install.python_packages(name = [
"torch==1.10",
"openmim"
])
install.conda_packages(channel= ["pytorch"], env_file = "env.yaml") # 指定路径下进行conda yaml环境安装
install.python_packages(requirements="build.txt") # 指定路径下进行requirments.txt安装
install.system_packages(name = [ # 系统依赖安装
"libgl1-mesa-glx"
])
run(commands=[
"mim install mmcv-full", # 通过第三方工具mim来进行安装
])
io.copy(src="./detectron2", dest="/") # 本地文件到镜像的拷贝
run(commands=[ # 离线进行依赖包安装
"pip install -e /detectron2",
])
def mirror_config(): #下载源配置
config.pip_index(url = "https://pypi.tuna.tsinghua.edu.cn/simple")
config.conda_channel(channel="""
channels:
- defaults
show_channel_urls: true
default_channels:
- https://repo.anaconda.com/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
""")
envd build --t 镜像名:TAG
学完这篇文章,你将会学会如何参与开源项目
在管理一个github项目的过程中三差五就会有新贡献者提交 PR 过来,但是多数贡献者在提交第一个 PR 时往往会遇到一个或多个问题,比如产生冲突、commits 记录过多或者混乱、commit 没有签名、commit message 不规范、各种 ci 流程检查报错等等。
那么今天我想尝试彻底讲明白“如何正确地提交一个 PR”,尝试细说 GitHub 上的 PR 全过程,以及这里面可能会遇到的各种困难和解决办法。一方面希望对第一次参与开源项目的新人有所帮助,另一方面希望能够进一步降低我们项目的参与门槛。
如果你就只是想开始参与开源,暂时还不知道该参与哪个社区,那么我有几个小建议:
开源项目的参与方式很多,最典型的方式是提交一个特性开发或者 bug 修复相关的 PR,但是其实文档完善、测试用例完善、bug 反馈等等也都是非常有价值的贡献。
GitHub 上的项目都有一个 Fork 按钮,我们需要先将开源项目 fork 到自己的账号下,以aiges为例:
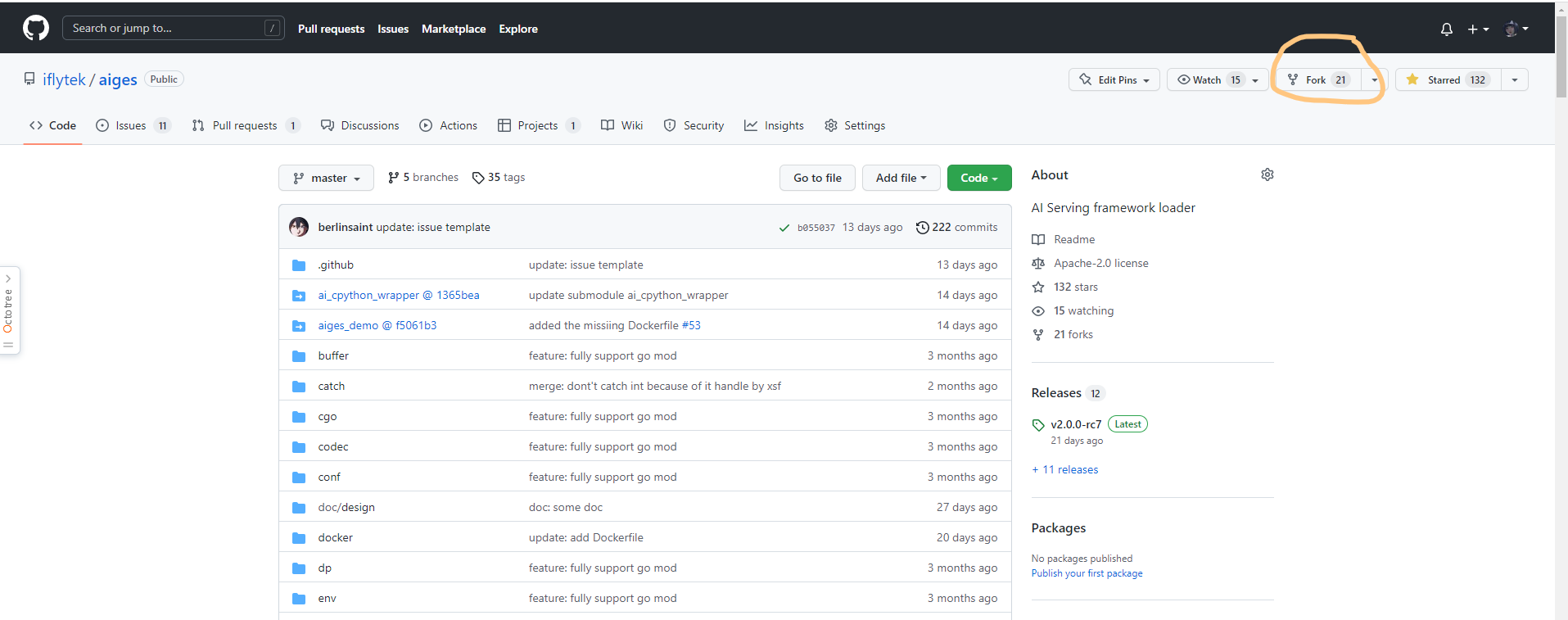 点一下 Fork 按钮,然后回到自己账号下,可以找到 fork 到的项目了:
点一下 Fork 按钮,然后回到自己账号下,可以找到 fork 到的项目了:
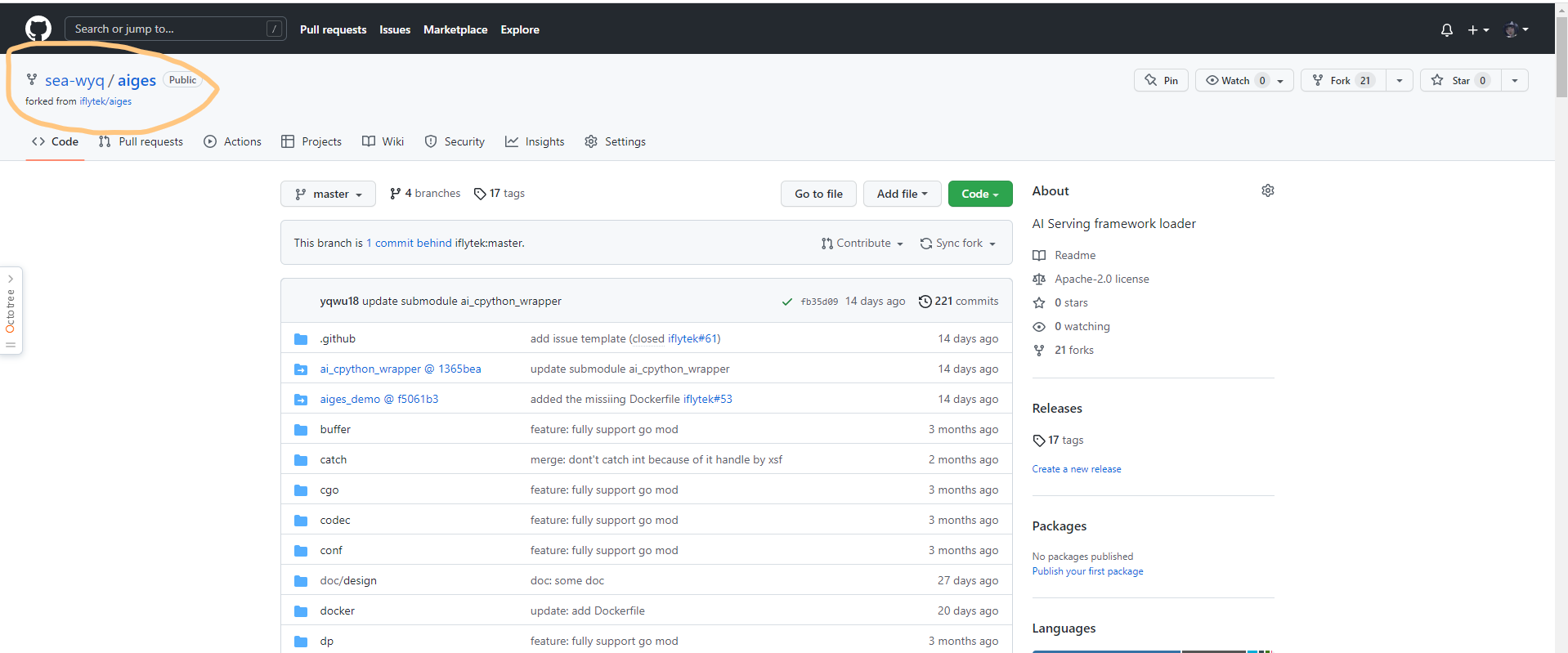 这个项目在你自己的账号下,也就意味着你有任意修改的权限了。我们后面要做的事情,就是将代码变更提到自己 fork 出来的代码库里,然后再通过 Pull Request 的方式将 commits 合入上游项目。
这个项目在你自己的账号下,也就意味着你有任意修改的权限了。我们后面要做的事情,就是将代码变更提到自己 fork 出来的代码库里,然后再通过 Pull Request 的方式将 commits 合入上游项目。
git clone https://github.com/sea-wyq/aiges.git
cd aiges
git remote add upstream https://github.com/iflytek/aiges.git
如果你配置好了 ssh 方式来 clone 代码,当然,git clone 命令用的 url 可以改成:git@github.com:iflytek/aiges.git。
完成这一步后,我们在本地看到的 remote 信息应该是这样的:
git remote -v
origin https://github.com/sea-wyq/aiges.git (fetch)
origin https://github.com/sea-wyq/aiges.git (push)
upstream https://github.com/iflytek/aiges.git (fetch)
upstream https://github.com/iflytek/aiges.git (push)
记住啰,你本地的代码变更永远只提交到 origin,然后通过 origin 提交 Pull Request 到 upstream。
如果你刚刚完成 fork 和 clone 操作,那么你本地的代码肯定是新的。但是“刚刚”只存在一次,接着每一次准备开始写代码之前,你都需要确认本地分支的代码是新的,因为基于老代码开发你会陷入无限的冲突困境之中。
更新本地 main 分支代码:
git fetch upstream
git checkout main
git rebase upstream/main
当然,我不建议你直接在 main 分支写代码,虽然你的第一个 PR 从 main 提交完全没有问题,但是如果你需要同时提交 2 个 PR 呢?总之鼓励新增一个 feat-xxx 或者 fix-xxx 等更可读的分支来完成开发工作。
创建分支:
git checkout -b feat-xxx
这样,我们就得到了一个和上游 main 分支代码一样的特性分支 feat-xxx 了,接着可以开始愉快地写代码啦!
没啥好说的,写就是了,写!
通用的流程:
git add <file>
git commit -s -m "some description here"
git push origin branchName
当然,这里大家需要理解这几个命令和参数的含义,灵活调整。比如你也可以用 git add --all 完成 add 步骤,在 push 的时候也可以加 -f 参数,用来强制覆盖远程分支(假如已经存在,但是 commits 记录不合你意)。但是请记得 git commit 的 -s 参数一定要加哦!
这里要注意 commit message 的规范,可能每个开源项目的要求不尽相同,比如 DevStream 的规范[6]是类似这样的格式:
<type>[optional scope]: <description>
[optional body]
[optional footer(s)]
举几个例子:
在完成 push 操作后,我们打开 GitHub,可以看到显示一个超前提交信息,告诉我们可以开一个 Pull Request 了:
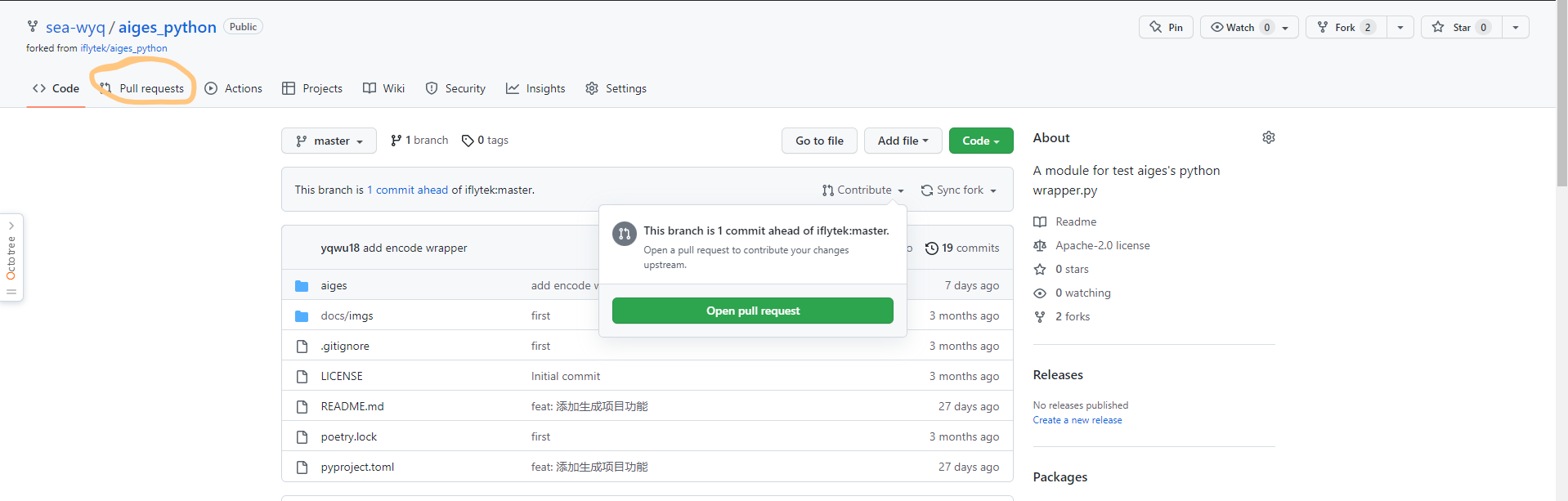
点击Pull Request 格式默认是这样的:
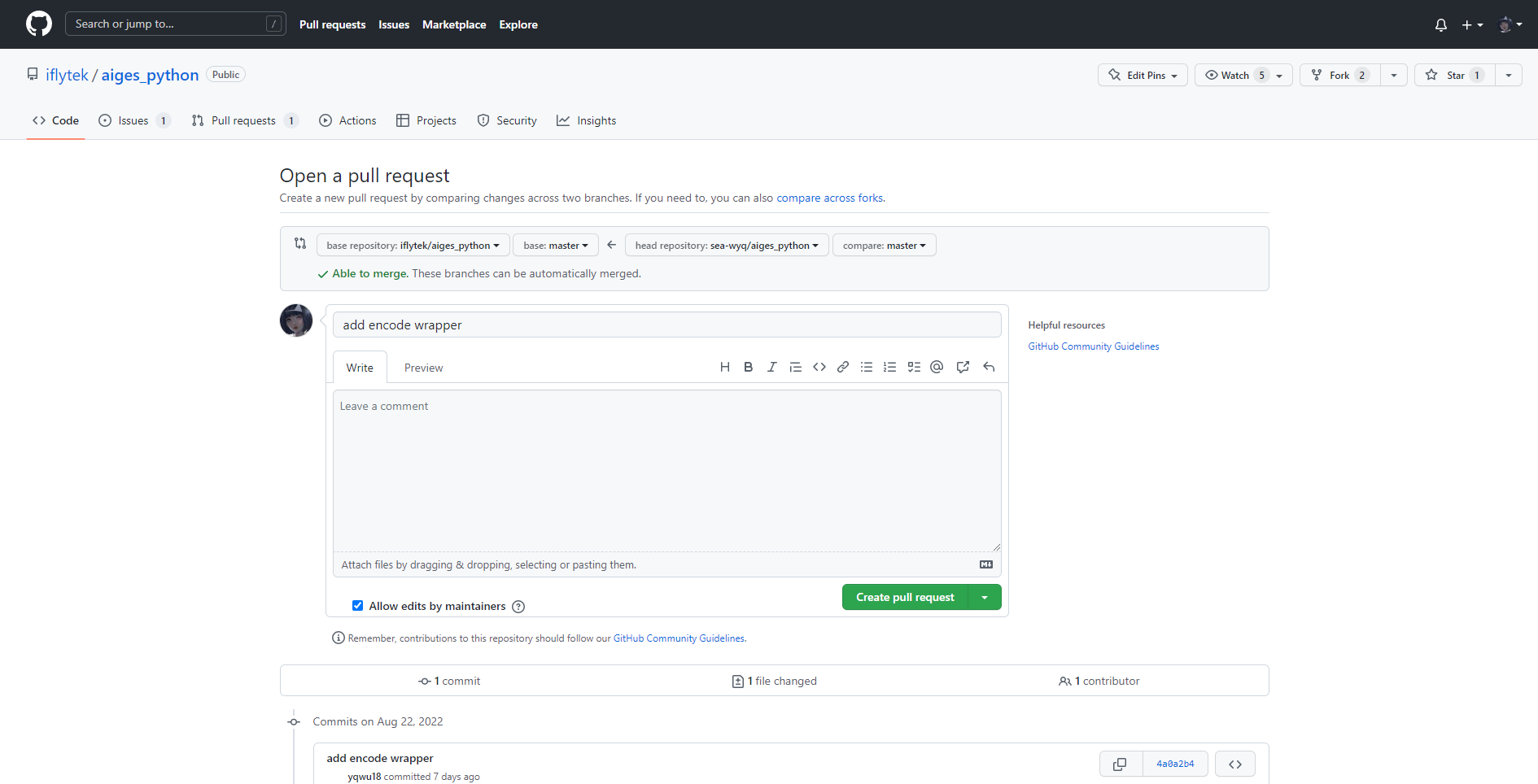
这里我们需要填写一个合适的标题(默认和 commit message 一样),然后按照模板填写 PR 描述。PR 模板其实在每个开源项目里都不太一样,我们需要仔细阅读上面的内容,避免犯低级错误。
填写完毕后,然后点击右下角 “Create pull request” 就完成了一个 PR 的创建了。
提交了 PR 之后,我们就可以在 PR 列表里找到自己的 PR 了,这时候还需要注意 ci 检查是不是全部能够通过,假如失败了,需要及时修复。
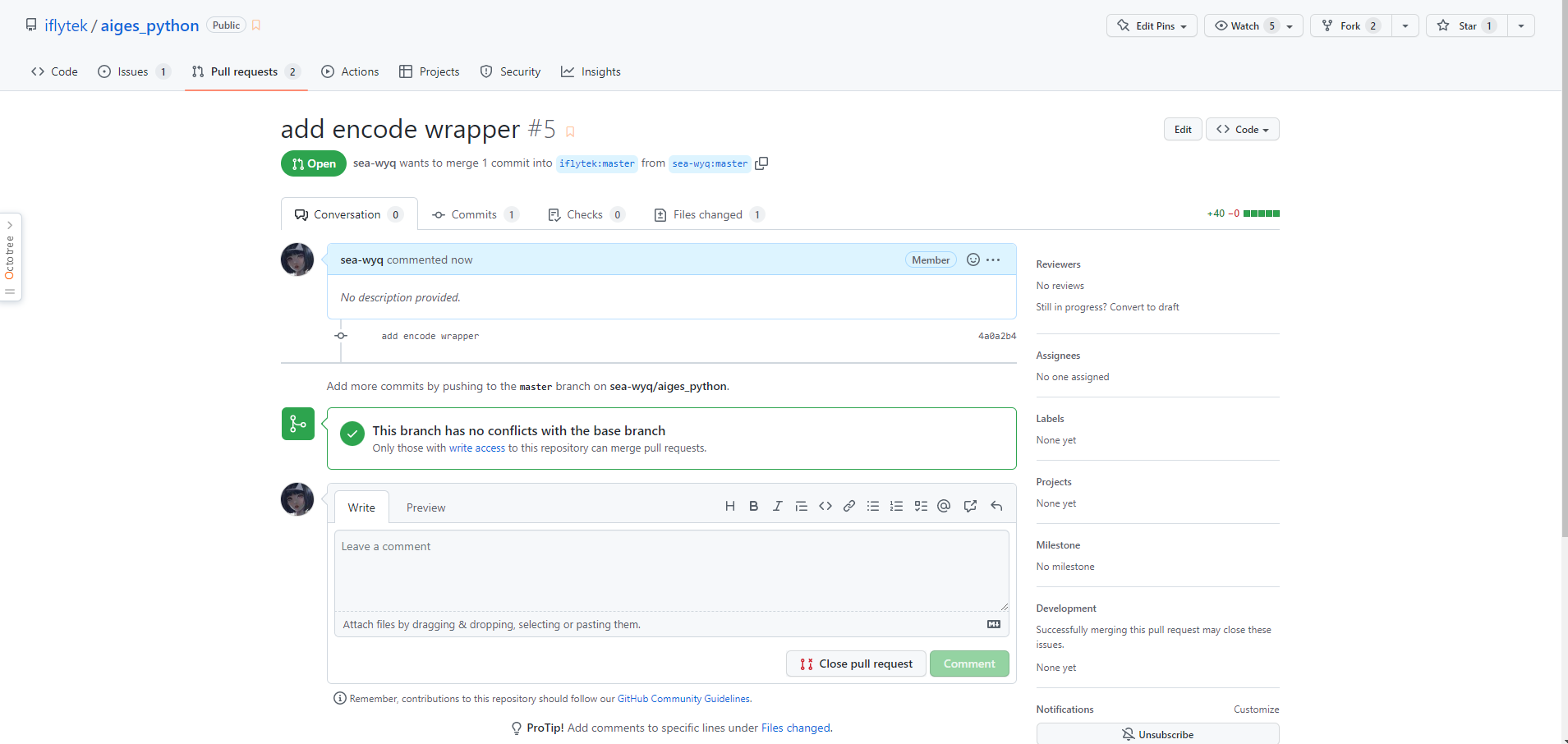
如果你的 PR 很完美,毫无争议,那么过不了太长时间,项目管理员会直接合入你的 PR,那么你这个 PR 的生命周期也就到此结束了。
但是,没错,这里有个“但是”,但是往往第一次 PR 不会那么顺利,我们接下来就详细介绍一下可能经常遇到的一些问题和对应的解决办法。
多数情况下,提交一个 PR 后是不会被马上合入的,reviewers 可能会提出各种修改意见,或者我们的 PR 本身存在一些规范性问题,或者 ci 检查就直接报错了,怎么解决呢?继续往下看吧。
很多时候,我们提交了一个 PR 后,还需要继续追加 commit,比如提交后发现代码还有点问题,想再改改,或者 reviewers 提了一些修改意见,我们需要更新代码。
一般我们遵守一个约定:在 review 开始之前,更新代码尽量不引入新的 commits 记录,也就是能合并就合并,保证 commits 记录清晰且有意义;在 review 开始之后,针对 reviewers 的修改意见所产生的新 commit,可以不向前合并,这样能够让二次 review 工作更有针对性。
不过不同社区要求不一样,可能有的开源项目会要求一个 PR 里只能包含一个 commit,大家根据实际场景灵活判断即可。
说回如何更新 PR,我们只需要在本地继续修改代码,然后通过和第一个 commit 一样的步骤,执行这几个命令:
git add <file>
git commit -s -m "some description here"
git push origin feat-xxx
这时候别看 push 的是 origin 的 feat-xxx 分支,其实 GitHub 会帮你把新增的 commits 全部追加到一个未合入 PR 里去。没错,你只管不断 push,PR 会自动更新。
至于如何合并 commits,我们下一小节具体介绍。
很多情况下我们需要去合并 commits,比如你的第一个 commit 里改了100 行代码,然后发现少改了 1 行,这时候又提交了一个 commit,那么第二个 commit 就太“没意思”了,我们需要合并一下。
比如我这里有2个同名的 commits,第二个 commit 其实只改了一个标点:
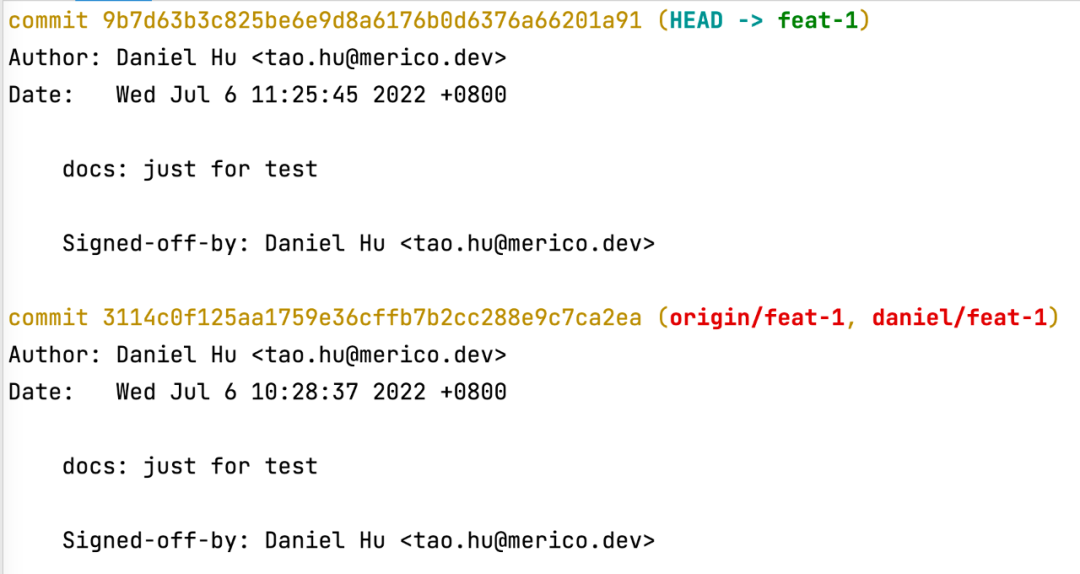 这时候我们可以通过 rebase 命令来完成2个 commits 的合并:
这时候我们可以通过 rebase 命令来完成2个 commits 的合并:
git rebase -i HEAD~2
执行这个命令会进入一个编辑页面,默认是 vim 编辑模式,内容大致如下:
pick 3114c0f docs: just fortest
pick 9b7d63b docs: just fortest
# Rebase d640931..9b7d63b onto d640931 (2 commands)
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
# d, drop = remove commit
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
我们需要把第二个 pick 改成 s,然后保存退出(vim 的 wq 命令):
pick 3114c0f docs: just fortest
s 9b7d63b docs: just fortest
接着会进入第二个编辑页面:
# This is a combination of 2 commits.
# This is the 1st commit message:
docs: just fortest
Signed-off-by: Daniel Hu <tao.hu@merico.dev>
# This is the commit message #2:
docs: just fortest
Signed-off-by: Daniel Hu <tao.hu@merico.dev>
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# ...
这里是用来编辑合并后的 commit message 的,我们直接删掉多余部分,只保留这样几行:
docs: just fortest
Signed-off-by: Daniel Hu <tao.hu@merico.dev>
接着同样是 vim 的保存退出操作,这时候可以看到日志:
[detached HEAD 80f5e57] docs: just fortest
Date: Wed Jul 6 10:28:37 2022 +0800
1 file changed, 2 insertions(+)
Successfully rebased and updated refs/heads/feat-1.
这时候可以通过git log命令查看下 commits 记录是不是符合预期:
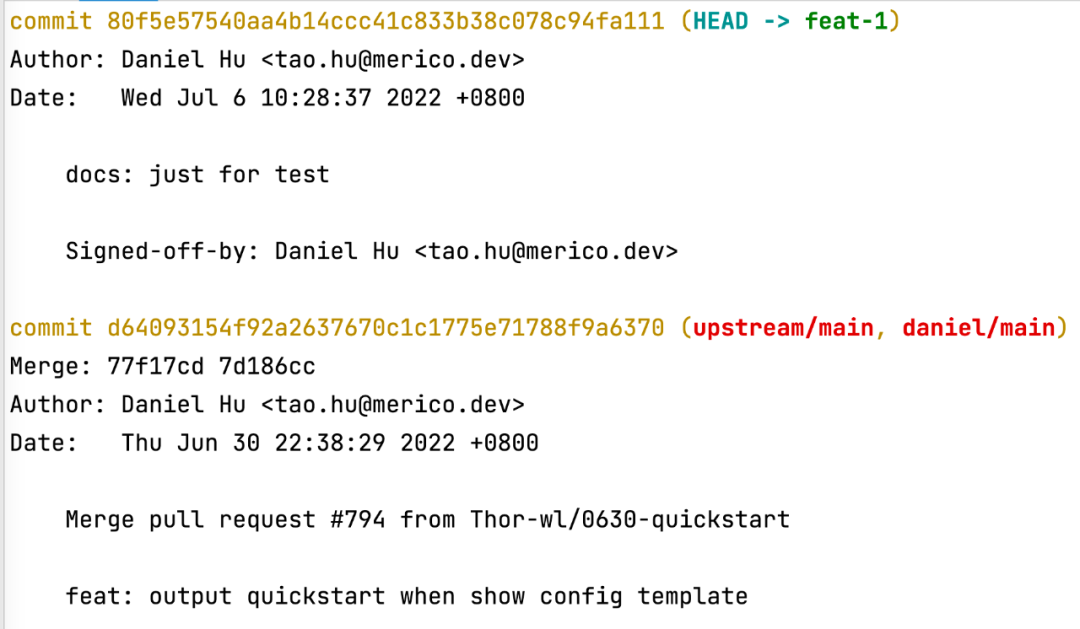
好,我们在本地确认 commits 已经完成合并,这时候就可以继续推送到远程,让 PR 也更新掉:
git push -f origin feat-xxx
这里需要有一个-f参数来强制更新,合并了 commits 本质也是一种冲突,需要冲掉远程旧的 commits 记录。
我们要尽可能避免冲突,养成每次写代码前更新本地代码的习惯。不过,冲突不可能完全避免,有时候你的 PR 被阻塞了几天,可能别人改了同一行代码,还抢先被合入了,这时候你的 PR 就出现冲突了,类似这样(同样,此刻我不能真的去上游项目构造冲突,所以下面用于演示的冲突在我在自己的 repo 里):
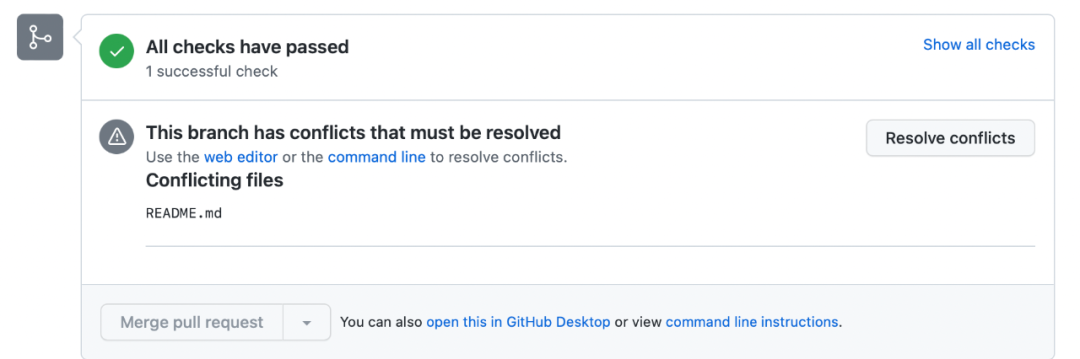 每次看到这个页面都会让人觉得心头一紧。我们点击 “Resolve conflicts” 按钮,就可以看到具体冲突的内容了:
每次看到这个页面都会让人觉得心头一紧。我们点击 “Resolve conflicts” 按钮,就可以看到具体冲突的内容了:
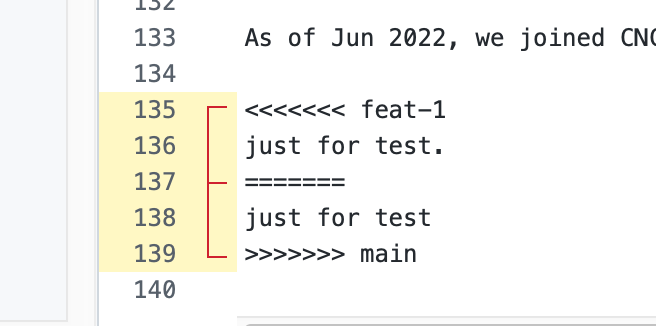 可以看到具体冲突的行了,接下来要做的就是解决冲突。我们需要删掉所有的 <<<<<<<、>>>>>>> 和 ======= 标记,只保留最终想要的内容,如下:
可以看到具体冲突的行了,接下来要做的就是解决冲突。我们需要删掉所有的 <<<<<<<、>>>>>>> 和 ======= 标记,只保留最终想要的内容,如下:
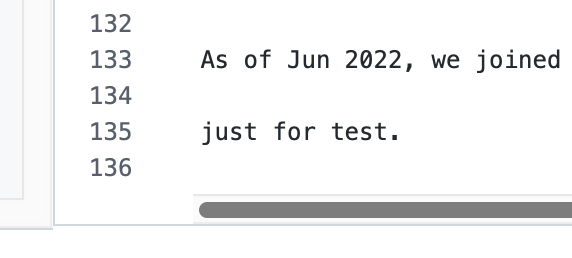 接着点击右上角的“Mark as Resolved”:
接着点击右上角的“Mark as Resolved”:
 最后点击“Commit merge”:
最后点击“Commit merge”:
 这样就完成冲突解决了,可以看到产生了一个新的 commit:
这样就完成冲突解决了,可以看到产生了一个新的 commit:
 到这里,冲突就解决掉了。
到这里,冲突就解决掉了。
更多时候,我们需要在本地解决冲突,尤其是冲突太多,太复杂的时候。
同样,我们构造一个冲突,这次尝试在本地解决冲突。
先在线看一下冲突的内容:
接着我们在本地执行:
# 先切回到 main 分支
git checkout main
# 拉取上游代码(实际场景肯定是和上游冲突,我们这里的演示环境其实是 origin)
git fetch upstream
# 更新本地 main(这里也可以用 rebase,但是 reset 不管有没有冲突总是会成功)
git reset --hard upstream/main
到这里,本地 main 分支就和远程(或者上游)main 分支代码完全一致了,然后我们要做的是将 main 分支的代码合入自己的特性分支,同时解决冲突。
git checkout feat-1
git rebase main
这时候会看到这样的日志:
First, rewinding head to replay your work on top of it...
Applying: docs: conflict test 1
Using index info to reconstruct a base tree...
M README.md
Falling back to patching base and 3-way merge...
Auto-merging README.md
CONFLICT (content): Merge conflict in README.md
error: Failed to merge in the changes.
Patch failed at 0001 docs: conflict test 1
The copy of the patch that failed is found in: .git/rebase-apply/patch
Resolve all conflicts manually, mark them as resolved with
"git add/rm <conflicted_files>", then run "git rebase --continue".
You can instead skip this commit: run "git rebase --skip".
To abort and get back to the state before "git rebase", run "git rebase --abort".
我们需要解决冲突,直接打开 README.md,找到冲突的地方,直接修改。这里的改法和上一小节介绍的在线解决冲突没有任何区别,我就不赘述了。
git push -f origin feat-xxx
这时候我们再回到 GitHub 看 PR 的话,可以发现冲突已经解决了,并且没有产生多余的 commit 记录,也就是说这个 PR 的 commit 记录非常干净,好似冲突从来没有出现过:
至于什么时候可以在线解决冲突,什么时候适合本地解决冲突,就看大家如何看待“需不需要保留解决冲突的记录”了,不同社区的理解不一样,可能特别成熟的开源社区会希望使用本地解决冲突方式,因为在线解决冲突产生的这条 merge 记录其实“没营养”。至于 DevStream 社区和 DevLake 社区,我们推荐使用后一种,但是不做强制要求。
前面我们提到过 commit message 的规范,但是第一次提交 PR 的时候还是很容易出错,比如 feat: xxx 其实能通过 ci 检查,但是 feat: Xxx 就不行了。假设现在我们不小心提交了一个 PR,但是里面 commit 的 message 不规范,这时候怎么修改呢?
太简单了,直接执行:
git commit --amend
这条命令执行后就能进入编辑页面,随意更新 commit message 了。改完之后,继续 push:
git push -f origin feat-xxx
这样就能更新 PR 里的 commit message 了。
相当多的开源项目会要求所有合入的 commits 都包含一行类似这样的记录:
Daniel Hu <tao.hu@merico.dev>
所以 commit message 看起来会像这样:
feat: some description here
Signed-off-by: Daniel Hu <tao.hu@merico.dev>
这行信息相当于是对应 commit 的作者签名。要添加这样一行签名当然很简单,我们直接在 git commit 命令后面加一个 -s 参数就可以了,比如 git commit -s -m "some description here" 提交的 commit 就会带上你的签名。
但是如果如果你第一次提交的 PR 里忘记了在 commits 中添加 Signed-off-by 呢?这时候,如果对应开源项目配置了 DCO 检查[8],那么你的 PR 就会在 ci 检查中被“揪出来”没有正确签名。
我们看下如何解决:
git commit --amend -s
这样一个简单的命令,就能直接在最近一个 commit 里加上 Signed-off-by 信息。执行这行命令后会直接进入 commit message 编辑页面,默认如下图:
docs: dco test
Signed-off-by: Daniel Hu <tao.hu@merico.dev
这时候我们可以同时修改 commit message,如果不需要,那就直接保存退出好了,签名信息是会自动加上的。
完成签名后呢?当然是来一个强制 push 了:
git push -f origin feat-xxx
这样,你 PR 中的 DCO 报错就自然修复了。

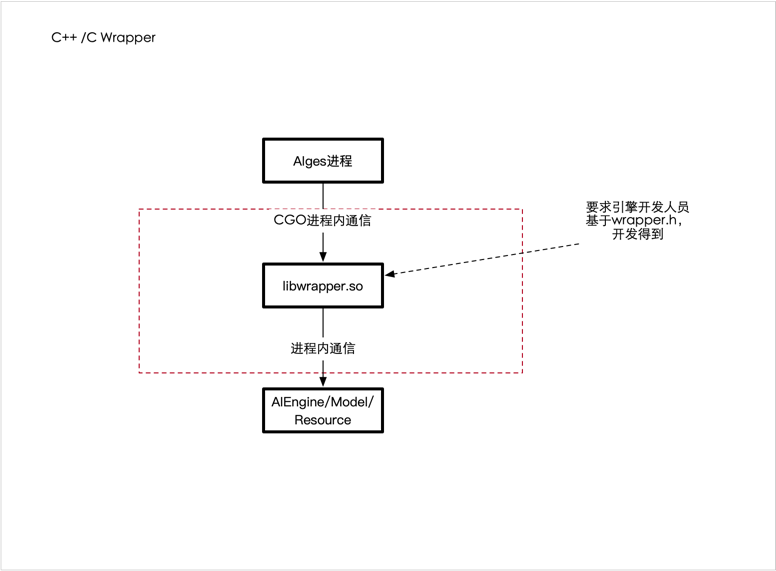
AI能力是指已完成云服务化的AI引擎。部署完成后,能力的使用者可以直接通过API和生成的接口文档进行集成及调用。具体定义可以参考ASE引擎名词解释
能力是通过加载器插件来调用。调用的能力不仅包含AI能力的使用,普通网络请求的调用同样适用。
对于非流式的网络请求——HTTP请求——来说,插件的主体包括四步;加载器的初始化;加载器的完成;加载器的执行;加载器的错误处理。分别对应了四个执行函数wrapperInit;wrapperFini;wrapperOnceExec;wrapperError。
通常加载器插件实现采用了C++语言,对于熟谙C++语言的用户来说毫无压力,当了解加载器插件的运行流程、数据输入和输出方式后,就可以实现自己的加载器插件,随即通过编译成动态库文件后可调用。
Python是一种弱类型语音,相比于C++,Python更小巧精悍,用户也能够更容易上手构建加载器插件。
本例主要介绍了一个调用三方音乐识别API的Python加载器插件实现步骤。调用音乐识别API时用户会发送待识别音乐的二进制流数据,音乐格式支持mp3、wav、wma、amr、ogg、ape、acc、spx、m4a、mp4、FLAC等,返回的识别结果是JSON对象。
加载器插件初始化函数wrapperInit用于初始化加载器执行过程中用到的变量,这些参数从配置文件config中读入,其中requrl是发送请求的地址。
global requrl, http_method, http_uri
global access_key_music, access_secret_music, access_key_humming, access_secret_humming
requrl, http_method, http_uri = config['requrl'], config['http_method'], config['http_uri']
access_key_music, access_secret_music = config['access_key_music'], config['access_secret_music']
access_key_humming, access_secret_humming = config['access_key_humming'], config['access_secret_humming']
加载器插件执行函数wrapperOnceExec的执行由鉴权、发送HTTP请求和接收响应数据构成。
鉴权的签名是通过http_method、http_uri、access_key、data_type、signature_version以及时间戳等来构建,构建过程如下:
signature_version, data_type = '1', 'audio'
timestamp = time.time()
string_to_sign = http_method + '\n' \
+ http_uri + '\n' \
+ access_key + '\n' \
+ data_type + '\n' \
+ signature_version + '\n' \
+ str(timestamp)
sign = base64.b64encode(hmac.new(access_secret.encode('ascii'), string_to_sign.encode('ascii'),
digestmod=hashlib.sha1).digest()).decode('ascii')
if sign is None:
logging.error('HMAC failure.')
return 5014
HTTP请求体可以看作一个字典,包括了请求数据、access_key、数据的长度、时间戳、签名、data_type和signature_version等。
构建的HTTP请求体如下:
files = {'sample': src}
data = {
'access_key': access_key,
'sample_bytes': sample_bytes,
'timestamp': str(timestamp),
'signature': sign,
'data_type': data_type,
'signature_version': signature_version
}
r = requests.post(requrl, files=files, data=data, timeout=5)
此外,在执行的过程中,错误需要尽可能早捕获,错误码也要和第三方平台区别开来,即使是默认的HTTP错误码也要有辨别也好,方便定位错误。
try:
r = requests.post(requrl, files=files, data=data, timeout=5)
except requests.exceptions.ConnectTimeout:
logging.error('Http post timeout.')
return 4408# http timeout
if r is None:
logging.error("HTTP内容非法")
return 4003
if r.status_code != 200:
return 4000 + r.status_code
请求的响应数据是JSON格式,有三个字段:
{
"cost_time":...
"status":...
"metadata":...
}
其中status字段中的code代表了响应的状态,为0表示请求成功,否则失败。所以应该判断code的取值,当不为零时则提前返回code表示的错误码
pattern = re.compile('"code":\d+')
error_code = re.findall(pattern, r.text)
error_code = error_code[0].split(':')[-1]
if int(error_code):
return int(error_code)
响应成功则返回一个预先定义好的字典表示:
r.encoding = 'utf-8'
respData.append({
'key': 'output_text',
'type': 0,
'status': 3,
"data": r.text,
"len": len(r.text.encode())
})
加载器插件错误处理函数wrapperError将会返回错误码代表的含义,在本例中如下
if ret == 1001:
return "识别无结果"
elif ret == 2000:
return "录音失败,可能是设备权限问题"
elif ret == 2001:
return "初始化错误或者初始化超时"
elif ret == 2002:
return "处理metadata错误"
elif ret == 2004:
return "无法生成指纹(有可能是静音)"
elif ret == 2005:
return "超时"
elif ret == 3000:
return "服务端错误"
elif ret == 3001:
return "Access Key不存在或错误"
elif ret == 3002:
return "HTTP内容非法"
elif ret == 3003:
return "请求数超出限制(需要升级账号)"
elif ret == 3006:
return "参数非法"
elif ret == 3014:
return "签名非法"
elif ret == 3015:
return "QPS超出限制(需要升级账号)"
else:
return f"User Defined Error: {ret}"
加载器插件完成函数wrapperFini用于处理一些加载器的收尾工作,在C++语言中里面会执行一些堆区和指针的释放,对于Python语言,通常不需要实现:
def wrapperFini() -> int:
logging.info('Wrapper finished.')
return 0
以上就是一个调用三方API的Python加载器实现的简单介绍 具体代码可以参考集成三方API实现Python加载器插件

随着近几年开源的蓬勃发展,开源的影响力在业内也是广泛被认可。以BAT为首的各行业的企业都在开源领域内发展其一些关键技术;一些关键的商业化场景更是以公司的开源实力来量化招标要求;
我司在几年前已经开展了一些开源的工作,也收集到集团内部一些零星的力量参与了开源社区的工作信息,总而言之,集团层面的开源工作没有形成有效的合力。
为此:
3月初,我们重新拾起了在几年前就已在Github开放代码的AthenaServing推理服务框架
6月,我们积极推进,最终集团正式成立了集团的开源工作组
7月25日,我们开展了第一次开源分享会,分享会上,我们对内宣发了开源工作成立的消息,同时,我们邀请了2位开源大咖给讯飞er们分享了一些非常有用的心路历程。
在集团内部,我们定义了一套基础的开源工作流
项目报备阶段 其中项目报备阶段有如下细分流程:
有意向开源需要向开源工作组提供如下信息:
此外,对开源有任何疑问的同学,也可以发邮件至开源工作组
项目代码内部评审
负责人先在内部评估计划开源代码开源范围,即功能清单(此举为保护部分非常商业化领域核心代码)
脱敏、并发起内部代码评审
评审定目标产物:
是否可开源
开源功能清单
注意: 代码评审会由项目负责人发起,最终提供给开源工作组结论即可。
项目代码成员确定
确定内部参与人员,以及角色分配
外部成员根据项目负责人邀请自行认定,但必须保证经过一系列有效代码提交。外部优秀开发者,可根据提交数量、质量向工作组推荐邀请进入Github 讯飞开源组织。 (此工作流待完善)
版本发布、更新
Github仓库
集团统一开源组织为iflytek, 当前组织管理员为 ybyang7
原则上,后续以公司名义开源的新项目需要统一在此组织下维护。
Github Member权限申请
Github iflytek组织Member的权限申请,可以发邮件至ifly_ospo
此流程为内部员工流程, 外部开发者进入组织权限将以github workflow形式自动化加入
邮件内容需提供:
Github项目目录
不同语言有不同的目录结构,除了基础的代码部分,项目目录推荐提供如下文件:
LICENSE文件: 一般推介(Apache2.0License)
.github/workflows/build.yml文件: Github Action配置文件,多用于自动构建
.github/workflows/release.yml文件: Github Action配置文件,多用于自动发布
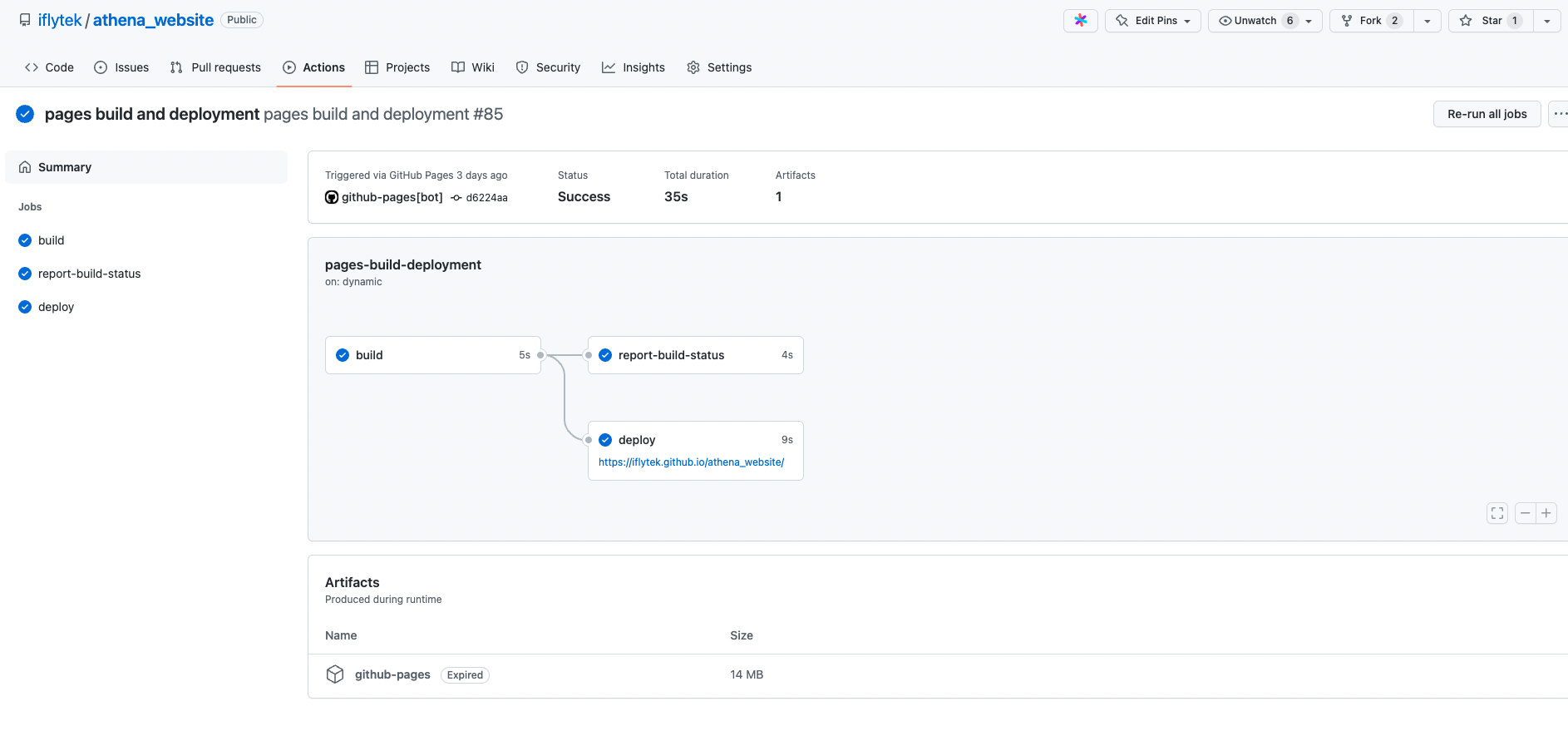
CI页面示例:
静态文档网站托管配置
Github提供了非常易用的静态网站托管功能,配合Github的CI工具: Github Action
以及一些三方文档生成工具如: Docusaurus, mkdocs,ASF Website就是利用 Docusaurus构建,并托管在github pages上。
周会机制
这里有两个层面周会:
1: 开源维护者交流周会(内部视角): 是需要定期向集团汇报开源进展的双周会(周期待调整) 集团内部开源项目负责人需要统一加入开源交流群,并定期报告进展。
2: 项目自身周会机制: 需要项目负责人根据各自项目开源进程自行发起并开展,推荐以公开在线会议方式开展,周期可以不用太频繁
自运营
开源工作组提供集团统一开源阵地以及门户,指导并规范每个开源项目的基础配置,但真正的项目是否能够良性运营取决于项目发起人及其部门对该开源项目的定位和价值分析,并且有一个可观的RoadMap。 开源虽然看起来似乎很简单,但它是一个需要长期投入的事情,同时做好了也是一件对企业影响力,个人影响力有极大加成的事情
请参考 如何从0参与开源项目
开源的工作是一个非常Open的工作,虽然很多时候是我们码农抽取自己的非工作时间来参与,我司虽然没有专门的开源岗位,但是开源本身这个事情在业界影响力对于每个开发人员来说也有目共睹。相信有一天,我司会为开源专门设立岗位,这一天需要每位有兴趣参与开源的同事共同努力,这一天一定不会远。
万事开头难, 我们在很多领域技术上都有一些起了个大早,却赶了个晚集,很大原因是由于我们没有坚持,另外我们不断的给自己设限,否定自己,我们开源不会成功,没有出路的思想经常萦绕在我们眼帘,找不到开源的出路和思路。
开源虽难,但未来可期!
还在想如何偷懒,直接复用研究员的Python代码进行在线推理?
还在寻找模型推理RPC->HTTP方案?
还在找 C/C++ 调用 Python, Python调用 C/C++技术方案?
还在找如何提速Python方案?
....
当前算法开发主流语言都是Python语言, 而想要落地成为生产级别服务应用,往往需要用C/C++等高阶语言进行复现并封装成高性能接口。
但是并非所有的场景都是需要高性能,任何服务接口的高性能的优化都是循序渐进的,目前很多厂商都会选择用Python进行实际推理, 讯飞当前拥有
一套Golang加载C插件方案,来支持当前讯飞主要的一些AI线上生产级别服务应用。
为了让用户更快速的接入Python实现的能力, 在当前讯飞AIGES架构基础上,利用Pybind11兼容了支持Python AI能力服务化。
Python Language Wrapper:
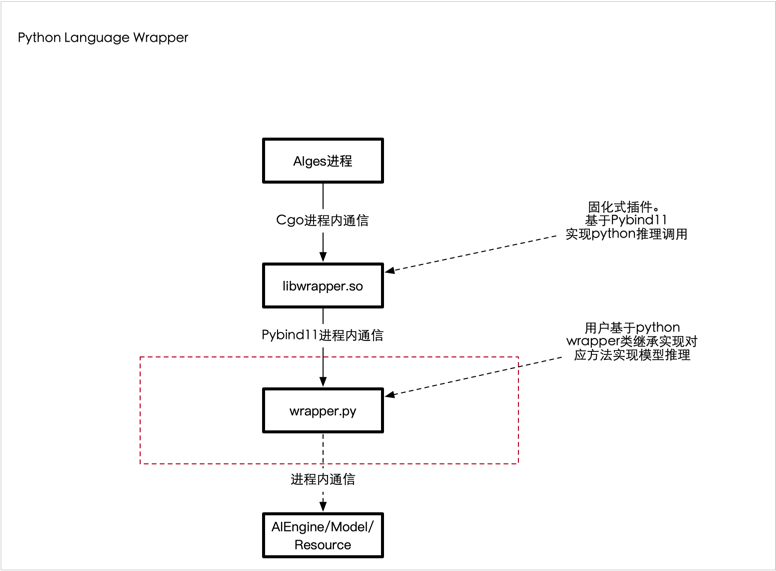
讯飞开源出品的 AthenaServing是一个将 Python AI能力(也可以支持C/C++)发布成为HTTP服务的 AI工程框架,详情请参考: Github
由上述架构可知, 我们需要使用C++调用Python能力(Golang无法直接调用Python,我们技术栈是Golang)。
传统的C调用Python,大多数人都会使用原生的Cpython形式去调用Python,我们在第一个版本时也是如此,其复杂度不言而喻,设计到Python的生命周期管理,内存管理,GIL,引用计数,对象转换等等...
Python 官方提供了 Python/C API,可以实现「用 C 语言编写 Python 库」,先上一段代码感受一下:
static PyObject *
spam_system(PyObject *self, PyObject *args)
{
const char *command;
int sts;
if (!PyArg_ParseTuple(args, "s", &command))
return NULL;
sts = system(command);
return PyLong_FromLong(sts);
}
上述是一个简单的对python system命令进行调用,却要进行多次手动类型转换,十分痛苦。。
Cython 主要打通的是 Python 和 C,方便为 Python 编写 C 扩展。Cython 的编译器支持转化 Python 代码为 C 代码,这些 C 代码可以调用 Python/C 的 API。从本质上来说,Cython 就是包含 C 数据类型的 Python。目前 Python 的 numpy,以及腾讯的 tRPC-Python 框架有所应用。
缺点: 需要手动植入 Cython 自带语法(cdef 等),移植和复用成本高 需要增加其他文件,如 setup.py、*.pyx 来让你的 Python 代码最后能够转成性能较高的 C 代码 对于 C++的支持程度存疑
SWIG 主要解决其他高级语言与 C 和 C++语言交互的问题,支持十几种编程语言,包括常见的 java、C#、javascript、Python 等。使用时需要用*.i 文件定义接口,然后用工具生成跨语言交互代码。但由于支持的语言众多,因此在 Python 端性能表现不是太好。
值得一提的是,TensorFlow 早期也是使用 SWIG 来封装 Python 接口,正式由于 SIWG 存在性能不够好、构建复杂、绑定代码晦涩难读等问题,TensorFlow 已于 2019 年将 SIWG 切换为 pybind11。
在pybind11 之前其实有一个boost.python库也是经典,但是它比较重度依赖 boost周边依赖库,比较庞大,经常让人望而却步.
pybind11 可以理解为boost.python的精简版,通过提供头文件,宏定义和元编程来简化 Python 的 API 调用。对 C++支持非常好,基于 C++11 应用了各种新特性,也许 pybind11 的后缀 11 就是出于这个原因。
特点:
如上述所示,我们为用户设计了class Wrapper类,用户需要实现Wrapper类中的必要方法,然后由C++读取该类并加载对应方法,当用户请求到达时,执行对应python方法,并返回得到相应数据完成一次推理请求。
我们重点看下 Wrapper 类的关键推理方法 wrapperOnceExec 方法, 该方
法函数定义为:
def wrapperOnceExec(self, params: {}, reqData: DataListCls) -> Response:
pass
其中 params 为该请求中的params请求参数映射,是一个字典,主要用于传递用户一些请求控制字段。
reqData 为该次请求的一些数据段,比如上传一个二进制图像,音频,文本等(此类参数不适合放入params中),reqData我们要求它必须是1个DataListCls类. 这个类有些特殊,因为我们的数据是来源于 C++,即从C++中传入数据到Python,因此这个请求必须在 c++侧构造,那么此处就涉及到 C++数据和Python数据的转换问题。
Pybind11提供了在C中定义内嵌(embed)python模块方式: 因此我们可以在C中给python很容易定义一个数据结构,比如此处:
class DataListNode {
public:
std::string key;
py::bytes data;
unsigned int len;
int type;
py::bytes get_data();
};
class DataListCls {
public:
std::vector <DataListNode> list;
DataListNode *get(std::string key);
};
DataListNode *DataListCls::get(std::string key) {
for (int idx = 0; idx < list.size(); idx++) {
DataListNode *node = &list[idx];
if (strcmp(node->key.c_str(), key.c_str()) == 0) {
return node;
}
}
return nullptr;
}
在c++中定义了两个类结构, 一个是 DataListCls 另一个是 DataListNode, 后者是前者的 list 变量成员。
我们的请求数据可以用 DataListCls 表示,那么该类数据传递到python函数如何被执行?
根据pybind11手册, 我们需要为上述2个类编写binding代码,如下:
PYBIND11_EMBEDDED_MODULE(aiges_embed, module
) {
py::class_<DataListNode> dataListNode(module, "DataListNode");
dataListNode.
def(py::init<>())
.def_readwrite("key", &DataListNode::key, py::return_value_policy::automatic_reference)
.def_readwrite("data", &DataListNode::data, py::return_value_policy::automatic_reference)
.def_readwrite("len", &DataListNode::len, py::return_value_policy::automatic_reference)
.def_readwrite("type", &DataListNode::type, py::return_value_policy::automatic_reference)
.def("get_data", &DataListNode::get_data, py::return_value_policy::reference);
py::class_<DataListCls> dataListCls(module, "DataListCls");
dataListCls.
def(py::init<>())
.def_readwrite("list", &DataListCls::list, py::return_value_policy::automatic_reference)
.def("get", &DataListCls::get, py::return_value_policy::reference);
}
PYBIND11_EMBEDDED_MODULE(aiges_embed, module) 宏用于定义一个 python的 aiges_embed模块,其内容为两个类的各个成员做了一个与python对应类的绑定动作:
其中使用 def_readwrite绑定可读写属性,使其与对应C类中成员变量。
其中使用 def绑定类方法,使其与对应C类中方法(有点类似于用c实现一套方法供用户在python中调用),上述 wrapperOnceExec方法在c++侧调用后, 执行到 python代码时, 如果执行 reqData.get方法,即会调用c++实现的get方法。
因为C++和python有不同的内存管理机制, 在为返回非普通类型的函数创建绑定时,这可能会导致问题。仅通过查看类型信息, Python侧不知道是否应该负责返回值并最终释放其资源,或者是否应该在 C++ 端处理内存的释放。为此,pybind11 提供了几个返回值策略 注解,可以传递给module::def()and class::def()函数。默认策略是
return_value_policy::automatic。
这块在绑定function时需要特别注意, 不合适的返回值策略可能会引发未知错误,因此此部分非常极其重要。
关于返回值策略,请参考文档
有了以上的binding之后, 在对应的python解释器生命周期中,可以直接使用 import aiges_embed 导入该c侧定义的Module以及其中的class类。
wrapper.py向您展示了导入 python侧的实现。
需要注意的是:
aiges_embed 库是用宏PYBIND11_EMBEDDED_MODULE在c侧进程中动态定义,因此aiges_embed库无法在本地的python lib目录中找到,这给我们本地调试带来一定的困难,即用户不清楚aige_embed中的DataListNode, DataListCls是如何实现,以及定义的。
因此,aiges这边做法是创建一个python的 sdk,供用户在使用Pure Python(没有c程序运行环境,只有python)环境调试wrapper.py逻辑.
我们在 sdk.dto实现c侧定义的相同类,所以你可以看到 wrapper.py的前两行:
try:
from aiges_embed import ResponseData, Response, DataListNode, DataListCls # c++
except:
from aiges.dto import Response, ResponseData, DataListNode, DataListCls
第一行导入执行成功的条件是,由c进程加载运行此wrapper.py
第二行导入执行成功的条件是,本地python环境模拟运行 wrapper.py时,此时依赖本地python库是否 安装过aiges依赖
使用 pip install aiges 即可完成安装。
注意
肯定有同学比较疑惑这个设计。 这个问题,我没有发现pybind11原生有何更优的解决方案,如有我不知道的,还请各位观众告知。
上述描述了C++传入数据到Python,用的是 DataListCls类的绑定, 返回其实也类似,也是实现类似绑定 Response
参见:
上述提到的在python的 aiges sdk中, 我们用python实现了对C程序的一个仿真,并且,在sdk中检查用户对 wrapper.py的编写是否有纰漏或者错误,提前暴露wrapper.py可能的编写问题。
wrapper.py的编写请移步: 实现第一个wrapper.py
一句话,当前状态未正式测试python性能,引用前同事一句话(你都开始用py了还考虑性能???)等下,这并不严谨,我道歉。python也是可以实现比较高的性能的, 且听我一段不负责任的嘴遁分析:
1: 当前主流的python推理实现,最终计算部分还是落在了python中的一些三方科学库中,如numpy,tensorflow等 c实现的类库中。 因此,比较负责任的一段解释是,如果你的推理插件中纯python的逻辑越少,那么理论上性能不会下降太多。一旦有一些复杂逻辑在python中用纯py实现,那么该处一定是一个性能下降点。
2: 如果ai能力要求输入一些大的二进制,比如图片,音视频,从C的内存到 Python的 bytes内存需要有一次拷贝,可能是一个性能下降点
3: 多说无益,具体情况具体分析
Python提供了一套 Buffer Protocol,基于它可以实现内存0拷贝,在不同的C插件中进行转移处理。
简而言之呢它是个什么玩意呢? 比如有一个大段的数据快(音视频),比如将它放在一个 array数组中,现在我们需要用 numpy去加载它,如果这个array数组是原生的python list,那么这一过程必然是有拷贝过程的。但是如果我们在c中利用 buffer protocol 设计出一种数据结构,这个数据结构传递到 numpy处理时,数据块可以直接指针转移,无需做数据拷贝,即可在numpy中处理该数据内存大块, 这在计算推理场景十分有用。
具体0拷贝以及 buffer protocol 的demo参考:
利用Python pybind11 我们可以用非常简洁的代码实现 C和python的互调用,这给我们AI工程化提供了更多的可能性。
本文部分参考(chao):
准备一台测试机(4c8G),硬盘>=20G即可
wget -c https://sealyun-home.oss-cn-beijing.aliyuncs.com/sealos-4.0/latest/sealos-amd64 -O sealos && chmod +x sealos && mv sealos /usr/bin
sealos run labring/kubernetes:v1.19.16 labring/calico:v3.22.1 --masters 192.168.64.2 -p <password>
sealos run labring/helm:v3.8.2 # install helmsealos run labring/openebs:v1.9.0 # install openebssealos run registry.cn-qingdao.aliyuncs.com/labring/athenaserving:v2.0.0rc1cd /var/lib/sealos/data/default/rootfs/athenaserving/charts/mmocr_ase
# 修改 demo.py中的 url部分为 nodeIP
python3 demo.py
调用结果:
200
HTTP API response is : [{'filename': '0', 'result': [{'box': [190, 37, 253, 31, 254, 46, 191, 52], 'box_score': 0.9566415548324585, 'text': 'nboroughofs', 'text_score': 1.0}, {'box': [253, 47, 257, 36, 287, 47, 282, 58], 'box_score': 0.9649642705917358, 'text': 'fsouthw', 'text_score': 1.0}, {'box': [157, 59, 188, 41, 194, 52, 163, 70], 'box_score': 0.9521175622940063, 'text': 'londond', 'text_score': 0.9897959183673469}, {'box': [280, 58, 286, 50, 306, 67, 300, 74], 'box_score': 0.9397556781768799, 'text': 'thwark', 'text_score': 1.0}, {'box': [252, 78, 295, 78, 295, 98, 252, 98], 'box_score': 0.9694718718528748, 'text': 'hill', 'text_score': 1.0}, {'box': [165, 78, 247, 78, 247, 99, 165, 99], 'box_score': 0.9548642039299011, 'text': 'octavia', 'text_score': 1.0}, {'box': [164, 105, 215, 103, 216, 121, 165, 123], 'box_score': 0.9806956052780151, 'text': 'social', 'text_score': 1.0}, {'box': [219, 104, 294, 104, 294, 122, 219, 122], 'box_score': 0.9688025116920471, 'text': 'reformer', 'text_score': 1.0}, {'box': [150, 124, 226, 124, 226, 141, 150, 141], 'box_score': 0.9752051830291748, 'text': 'established', 'text_score': 1.0}, {'box': [229, 124, 255, 124, 255, 140, 229, 140], 'box_score': 0.94972825050354, 'text': 'this', 'text_score': 1.0}, {'box': [259, 125, 305, 123, 306, 139, 260, 142], 'box_score': 0.9752089977264404, 'text': 'garden', 'text_score': 1.1666666666666667}, {'box': [166, 142, 193, 141, 194, 156, 167, 157], 'box_score': 0.9731062650680542, 'text': 'hall', 'text_score': 1.0}, {'box': [198, 142, 223, 142, 223, 156, 198, 156], 'box_score': 0.9548938870429993, 'text': 'and', 'text_score': 1.0}, {'box': [228, 144, 286, 144, 286, 159, 228, 159], 'box_score': 0.977089524269104, 'text': 'cottages', 'text_score': 1.25}, {'box': [180, 158, 205, 158, 205, 172, 180, 172], 'box_score': 0.9400062561035156, 'text': 'and', 'text_score': 1.0}, {'box': [210, 160, 279, 158, 279, 172, 210, 174], 'box_score': 0.9543584585189819, 'text': 'pioneered', 'text_score': 1.0}, {'box': [226, 176, 277, 176, 277, 188, 226, 188], 'box_score': 0.9748533964157104, 'text': 'cadets', 'text_score': 1.0}, {'box': [183, 177, 223, 177, 223, 189, 183, 189], 'box_score': 0.9633153676986694, 'text': 'army', 'text_score': 1.0}, {'box': [201, 190, 235, 190, 235, 204, 201, 204], 'box_score': 0.9714152216911316, 'text': '1887', 'text_score': 1.25}, {'box': [175, 213, 180, 201, 211, 212, 206, 225], 'box_score': 0.9704344868659973, 'text': 'vted', 'text_score': 0.9191176470588236}, {'box': [241, 213, 278, 200, 283, 213, 246, 227], 'box_score': 0.9607459902763367, 'text': 'epeople', 'text_score': 1.0}, {'box': [208, 224, 210, 212, 223, 214, 220, 227], 'box_score': 0.9337806701660156, 'text': 'by', 'text_score': 1.0}, {'box': [223, 214, 240, 214, 240, 226, 223, 226], 'box_score': 0.969144344329834, 'text': 'the', 'text_score': 1.0}]}]
########################################
MMocr Result: box located at [190, 37, 253, 31, 254, 46, 191, 52], box score is 0.9566415548324585. Detected text is nboroughofs , text score is 1.0...
MMocr Result: box located at [253, 47, 257, 36, 287, 47, 282, 58], box score is 0.9649642705917358. Detected text is fsouthw , text score is 1.0...
MMocr Result: box located at [157, 59, 188, 41, 194, 52, 163, 70], box score is 0.9521175622940063. Detected text is londond , text score is 0.9897959183673469...
MMocr Result: box located at [280, 58, 286, 50, 306, 67, 300, 74], box score is 0.9397556781768799. Detected text is thwark , text score is 1.0...
MMocr Result: box located at [252, 78, 295, 78, 295, 98, 252, 98], box score is 0.9694718718528748. Detected text is hill , text score is 1.0...
MMocr Result: box located at [165, 78, 247, 78, 247, 99, 165, 99], box score is 0.9548642039299011. Detected text is octavia , text score is 1.0...
MMocr Result: box located at [164, 105, 215, 103, 216, 121, 165, 123], box score is 0.9806956052780151. Detected text is social , text score is 1.0...
MMocr Result: box located at [219, 104, 294, 104, 294, 122, 219, 122], box score is 0.9688025116920471. Detected text is reformer , text score is 1.0...
MMocr Result: box located at [150, 124, 226, 124, 226, 141, 150, 141], box score is 0.9752051830291748. Detected text is established , text score is 1.0...
MMocr Result: box located at [229, 124, 255, 124, 255, 140, 229, 140], box score is 0.94972825050354. Detected text is this , text score is 1.0...
MMocr Result: box located at [259, 125, 305, 123, 306, 139, 260, 142], box score is 0.9752089977264404. Detected text is garden , text score is 1.1666666666666667...
MMocr Result: box located at [166, 142, 193, 141, 194, 156, 167, 157], box score is 0.9731062650680542. Detected text is hall , text score is 1.0...
MMocr Result: box located at [198, 142, 223, 142, 223, 156, 198, 156], box score is 0.9548938870429993. Detected text is and , text score is 1.0...
MMocr Result: box located at [228, 144, 286, 144, 286, 159, 228, 159], box score is 0.977089524269104. Detected text is cottages , text score is 1.25...
MMocr Result: box located at [180, 158, 205, 158, 205, 172, 180, 172], box score is 0.9400062561035156. Detected text is and , text score is 1.0...
MMocr Result: box located at [210, 160, 279, 158, 279, 172, 210, 174], box score is 0.9543584585189819. Detected text is pioneered , text score is 1.0...
MMocr Result: box located at [226, 176, 277, 176, 277, 188, 226, 188], box score is 0.9748533964157104. Detected text is cadets , text score is 1.0...
MMocr Result: box located at [183, 177, 223, 177, 223, 189, 183, 189], box score is 0.9633153676986694. Detected text is army , text score is 1.0...
MMocr Result: box located at [201, 190, 235, 190, 235, 204, 201, 204], box score is 0.9714152216911316. Detected text is 1887 , text score is 1.25...
MMocr Result: box located at [175, 213, 180, 201, 211, 212, 206, 225], box score is 0.9704344868659973. Detected text is vted , text score is 0.9191176470588236...
MMocr Result: box located at [241, 213, 278, 200, 283, 213, 246, 227], box score is 0.9607459902763367. Detected text is epeople , text score is 1.0...
MMocr Result: box located at [208, 224, 210, 212, 223, 214, 220, 227], box score is 0.9337806701660156. Detected text is by , text score is 1.0...
MMocr Result: box located at [223, 214, 240, 214, 240, 226, 223, 226], box score is 0.969144344329834. Detected text is the , text score is 1.0...

systemctl stop firewalld
systemctl disable firewalld
setenforce 0
hostnamectl set-hostname master
hostnamectl set-hostname node1
# 节点ip通过各节点ipconfig获取
cat <<EOF >> /etc/hosts
172.31.1.36 master
172.31.11.161 node1
EOF
ssh-keygen
ssh-copy-id root@master
ssh-copy-id root@node1
# 下载sealos
wget -c https://sealyun-home.oss-cn-beijing.aliyuncs.com/sealos/latest/sealos &&
chmod +x sealos && mv sealos /usr/bin
# 下载kubelete-1.22版本离线资源包
wget -c https://sealyun.oss-cn-beijing.aliyuncs.com/05a3db657821277f5f3b92d834bbaf98-v1.22.0/kube1.22.0.tar.gz
# 部署k8s集群
sealos init \
--passwd 123456 \
--master 172.31.1.36 \
--node 172.31.11.161 \
--pkg-url /home/ubuntu/kube1.22.0.tar.gz \
--version v1.22.0
helm add repo openebs https://openebs.github.io/charts
helm pull openebs/openebs
# 修改服务对应的storageclass即可
#默认持久化数据地址:/var/openebs/local
# 安装openebs
helm install ebs openebs
https://github.com/sea-wyq/Athena_deploy.git
cd Athena_deploy/chart/
helm install athena athenaserving
服务集群搭建成功。。。
Welcome to contribute AthenaServing Docs and Blogs.

Lorem ipsum dolor sit amet, consectetur adipiscing elit. Pellentesque elementum dignissim ultricies. Fusce rhoncus ipsum tempor eros aliquam consequat. Lorem ipsum dolor sit amet 。